BrainVoyager QX v2.8
Exploiting the Power of GP-GPUs
Background
Since many years, BrainVoyager uses central processing unit (CPU) based parallelization to speed up performance by exploiting the compute power of multiple processors and multiple processor cores. Increasing the number of processor cores is one of the major approaches to improve the computational power of modern processors since the clock speed can no longer increase substantially as in previous decades. To benefit from multiple processors and multiple cores, software has to be "multi-threaded", i.e. the computational routines are coded in a way that sub-problems can be run concurrently. Massive parallelism has, however, not yet achieved with this approach since the number of processors and cores in standard computers is limited, i.e. 2 or 4 cores in current laptops and a few processors with 4 or 8 cores on high-end workstations. Massive parallelism would be very advantageous in neuroimaging since many algorithms can be parallelized at the level of voxels and vertices, i.e. it would benefit from the possibility to run thousands of sub-problems concurrently. Massive parallelism is precisely where modern graphics cards come into play since their architecture is primarily constructed to optimally support graphics calculations that are inherently parallel since they were originally build to parallelize graphical calculations at the level of vertices of 3D meshes as well as at the level of pixels. Early graphics boards were optimized to support 3D standards like OpenGL and DirectX (used mainly to implement 3D games) used fixed processing pipelines, i.e. they could only do preprogrammed graphics calculations. Modern graphics cards, in contrast, contain general purpose processing on graphics processing units (GP-GPUs) that are programmable allowing to use the massive parallel architecture for general calculations. With hundreds to thousands of simple, but programmable, processing cores, these modern graphic cards enable massively parallelized computations for algorithms that can be recoded appropriately. Writing parallelized code that exploit the large number of graphics cores will, thus, provide high performance computing (HPC). Depending on the graphics card, the observed speed gain is typically in the order of 10 - 100 as compared to single-threaded CPU performance. While significant speed gains may already be observed on laptops, speed gains of 100 or more may require workstations equipped with one or more powerful GP-GPUs of the latest generations.
In order to program GP-GPUs several graphics vendor specific APIs are available, such as Cuda for NVIDIA boards. As an alternative, the Khronos group has developed OpenCL (Open Computing Language) as a cross-platform standard for parallel programming for GP-GPUs and CPUs that is supported by major computer and graphics card companies including Apple, Intel, NVIDIA, ATI. Using OpenCL, the same parallelized programs can be used to run on many graphics boards and CPUs; because there are so many different graphics boards (and CPUs), OpenCL code is actually compiled into executable code on the graphics card of the user itself. BrainVoyager QX 2.6 and later uses OpenCL to speed up computations on GP-GPUs and optionally also for computation on multi-core CPUs (besides classical multi-threaded code). to support OpenCL it may be necessary to install the latest graphics driver from NVIDIA or ATI depending on the used graphics board. The Khronos group also maintains a list of graphics cards that are compatible with OpenCL.
OpenCL parallelizes computation by executing multiple "work-items" at the same time, similar to running multiple threads in a multi-threaded application in, e.g., C++. The first routines that benefit from OpenCL code are sinc interpolation and sigma filtering. For running these operations using OpenCL, users can choose between four different implementations. While they all implement the same functionality, they differ in how the workload is parallelized and which features of OpenCL are used. Which implementation works best depends on the hardware (graphics card or processor), so users who want to find the fastest way to do sinc interpolation and sigma filtering are encouraged to test different settings. The following is a short description of each implementation:
- One work-item per (x, y). This implementation uses one work-item for each XY coordinate; each work-item contains a loop going from z=0 to the highest z-coordinate.
- Local work-group size. This implementation uses one work-item per voxel, with the work-items organized into “work-groups” of 64. Each group processes a block of 4×4×4 voxels. This way, work-items responsible for neighboring voxels are likely to run in the same group, which means that there is more overlap in the input data required by the work-items in a group. Because the work-items of a work-group are often run together, this can make memory access more efficient.
- Using image objects. This implementation is identical to the previous one, except that it uses “image objects” to store input data. Image objects are OpenCL's way of making the optimized support for textures (2-D and 3-D images) in graphics cards available. As a result, this implementation is faster on some GPUs, but may not work on CPUs.
- Using 4-element vectors. This implementation is optimized for use on CPUs, rather than graphics cards. It takes advantage of the SSE (Streaming SIMD Extensions) instructions present in modern CPUs by using four-element vectors to represent coordinates.
Note that since OpenCL is usually running on the graphics card, no display refreshes are performed during lengthy calculations and the computer might appear as hanging. To avoid this, BrainVoyager splits computation done with OpenCL in multiple parts, where each part is executed after the previous one completes. Between the executed parts, the graphics card can shortly be used for standard display purposes. This allows to show a progress bar and to let the user cancel a long computation, but, depending on hardware, the partitioning of a lengthy routine in smaller parts may come at a cost in performance. In a future version, the user may fine-tune the default responsiveness settings. Furthermore, additional compute-intense algorithms of BrainVoyager that benefit from massive parallelization will be rewritten in OpenCL.
Application
Since BrainVoyager QX 2.6 it is possible to run non-graphical compute-intense algorithms directly on the graphics board. More specifically, sinc interpolation and sigma filtering can now be performed on the GPU. Sinc interpolation is especially important since it can be used in many compute-intensive routines, including motion correction, VTC creation and general VMR, VMP and VTC spatial transformations. Because it achieves best interpolation results, sinc interpolation is usually recommended but it is not often used since it takes much time on standard (even multi-core) CPUs. Depending on the graphics hardware, the new GPU implementation achieves results that lead from modest to dramatic reductions in calculation time.
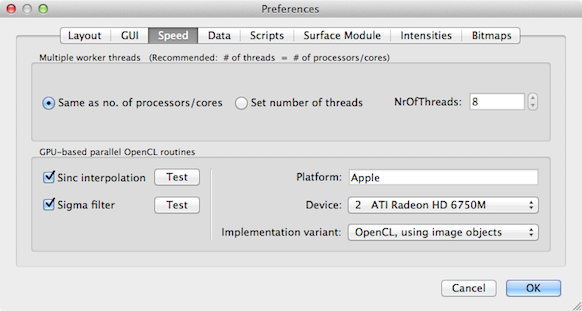
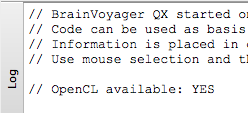
GPU-based sinc interpolation and sigma filtering can be enabled and tested using the Speed tab of the Preferences dialog (see snapshot above). The settings made in this dialog will be stored permanently, i.e. they will be in effect also in future BrainVoyager sessions. If your computer does not support GP-GPU-based calculations, the GPU-based parallel OpenCL routines field will be disabled. You may also see whether your computer supports OpenCL by looking in the Log pane since BrainVoyager checks for OpenCL during start-up. The snapshot below shows that OpenCL is supported.
If OpenCL is supported, you may enable GPU-based sinc interpolation, simply by checking the Sinc interpolation and Sigma filter option in the GPU-based parallel OpenCL routines field. You may also test which specific variant of code implementation provides best results, i.e. the shortest calculation time. This requires that you enter the Preferences dialog from a VMR window since the test routines operate on the currently active window in the workspace. Several slightly different OpenCL implementations are provided since different graphics boards handle certain optimization features in different ways (for details see Background section above). Select one of the provided implementations in the Implementation variant box.
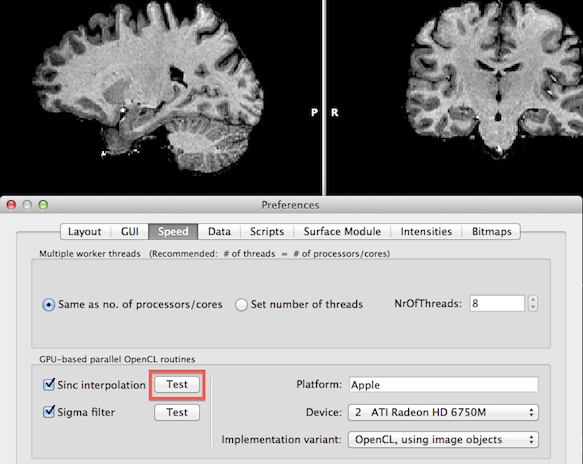
To test the performance of the selected implementation variant, click the Test button next to the Sinc interpolation option or Sigma filter option (see snapshot above). After clicking the sinc interpolation Test button, for example, a preset spatial transformation will be performed using sinc interpolation for the currently selected VMR data set (see snapshot below). The processing time (duration in milliseconds) will be printed in the Log pane. Furthermore, in order to not change the current VMR data set, the program offers to revert back to the original VMR data. If you do not want to revert back to the original data set, click the Cancel button in the appearing OpenCL Test dialog; you may then close the Preferences dialog and use the mouse to explore the changed VMR data set. If you want to undo the VMR changes later on, you can click the Reload All button in the Segmentation tab of the VMR's Volume Tools dialog.
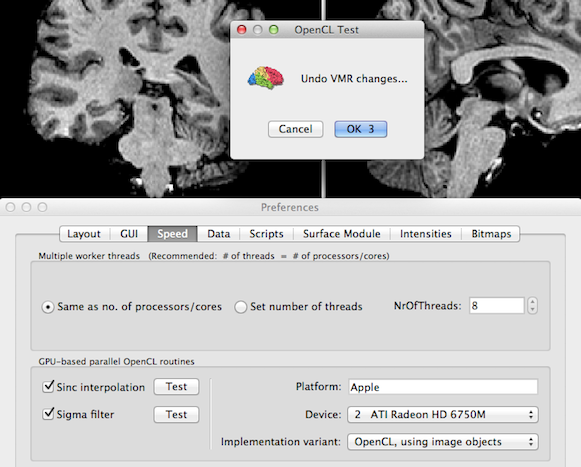
To find out the best implementation variant for OpenCL performance on your computer, you may test the different versions and select the one providing best performance before leaving the Preferences dialog by clicking the OK button. If graphics memory is limited, you may experience error messages when using VMR data sets with large dimensions (e.g. 512) but not with smaller dimensions (e.g. 256).
If the Sinc interpolation option is turned on, the selected OpenCL implementation will be used automatically in most spatial transformation routines, including motion correction, VMR and VMP transformations in case sinc interpolation is turned on for these operations. Since BrainVoyager QX 2.8, also native, ACPC and Talairach space VTC creation uses GPU-based sinc interpolation if enabled. If the Sigma filter option is turned on, it will be used automatically when issuing a sigma filter operation in the Volume Tools dialog.
Check Rainer's BV Blog for a blog entry in the near future providing further details on OpenCL and performance benchmarks for some computer platforms.
Copyright © 2013 Rainer Goebel and Levin Fritz. All rights reserved.