BrainVoyager QX v2.8
ROI-SVM Batch Processing
Applying SVM classifiers to many ROIs one by one involves a lot of "clicking" work. Also running cross-validation tests at the level of runs by splitting data in training/test sets requires a lot of GUI work. In order to simplify and speed-up analyses, BrainVoyager QX provides batch processing tools (since version 2.6) that are available in the Batch processing field of the ROI-SVM tab of the Multi-Voxel Pattern Analysis dialog.
Analyzing multiple ROIs
In order to run SVM classifiers for multiple ROIs in one go, check the Run for all ROIs option. The program will then use all ROIs in the VOI/VOM list of the ROI-based feature selection field. Since VOM files currently support only 1 ROI, it is advised to use a .voi file with multiple defined ROIs. If the Run for all ROIs option is not chosen, the program will use a single ROI that is selected in the VOI/VOM list. For each ROI in turn, training/testing data for the voxels in the ROI is created from provided data in the Trial data (all voxels) field. The training runs list (and eventually the testing runs list) need, thus, to be filled with the desired whole-brain trial data (VMP files) before starting batch processing. You need to provide testing data in case that the Separate training / test runs option is selected in the Create ROI-MVPA data field. This option is only used in case that batch processing is started with the No splitting option. In case that the run-level or trial-level splitting option is used, only the training runs list needs to be filled. In order to launch batch processing, finally click the GO button in the Batch processing field.
Analyzing multiple ROIs with Run-Level Splitting
Cross-validation at run-level is usually a recommended approach to evaluate the performance of a classifier (e.g. Mitchell tutorial). In a "leave-one-run-out" cross validation approach, for example, each run is set aside once as test data while training is performed using all other runs. If, for example, a data set contains 5 runs, five data splits would be created with the first run used as test data in the first split, the second run in the second split and so on. After training has finished for a split, the respective test run is used to evaluate the generalization performance of the trained classifier; the overall performance is finally assessed by integrating the achieved performance across all data splits.
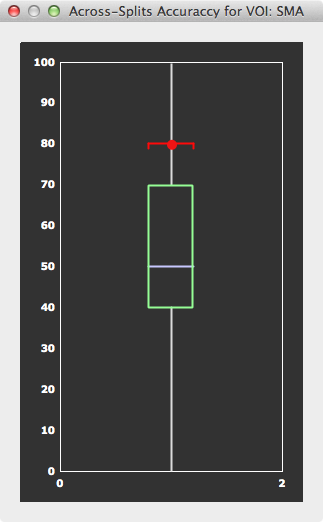
This run-level cross-validation approach can be applied automatically when selecting the Use run-level splits option in the Batch processing field. Furhermore, it will be applied to all ROIs in the way described in the previous section. For each ROI, the resulting performance will be printed in the Log pane for each split and for the average performance across all splits. In case that the Perm test option is also selected, the significance of the accuracy is also evaluated by permutation testing as described in the Assessing the Significance of SVMs topic. With this option, permutation testing is performed for each split and the null distribution will be reported in the Log pane. More importantly, the null distributions from all splits are combined at the end of ROI processing providind a robust null distribution to which the average test accuracy score will be related. The calculated overall result for each processed ROI is reported in the Log pane and graphically as a box-and-whisker plot (see snapshot above); the title of the plot dialog will report to which ROI the information belongs. Since the null distribution is pooled across all splits, the number of permutations in the number of permutations (no.) spin box need not to be set as high as when using a single training/test data partitioning scheme. If, for example, the number of permutations is set to 100 (default), in total number-of-runs x 100 permutations will be performed.
Copyright © 2014 Rainer Goebel. All rights reserved.